BoundingPulse
2023–2024National Craigslist search — a nationwide scraper and full-stack analytics platform. (creds in overview)
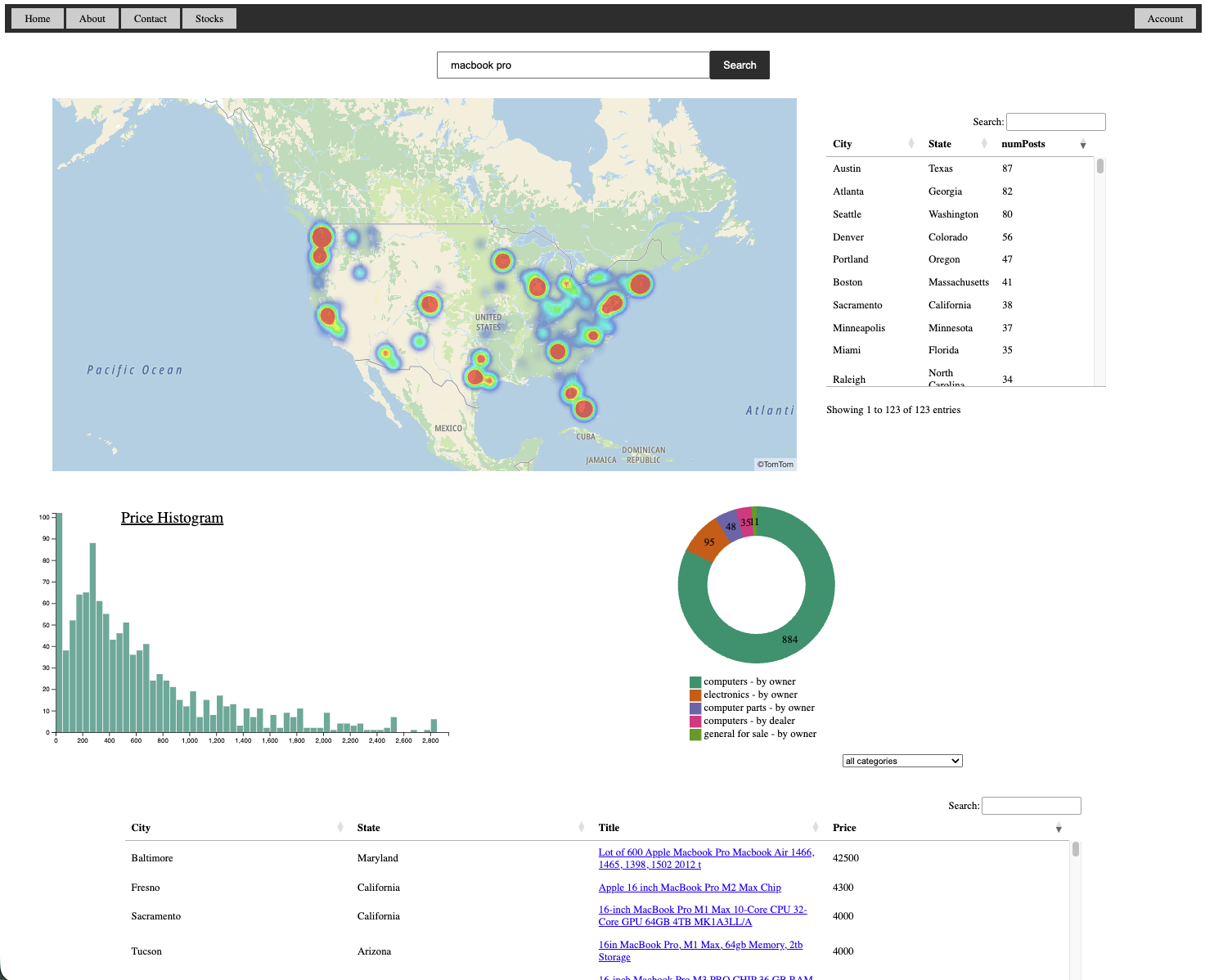
Overview
BoundingPulse grew out of craigSearch, a Python tool that automated and filtered Craigslist searches beyond what the site itself allows. It evolved into a full-stack, AWS-hosted analytics platform that ingests Craigslist posts nationwide for geographic cost insights, with text indexing for advanced search — all backed by a scraping + database pipeline.
-> boundingpulse.com user: silas pw: password
Motivation
One day I was interested in buying a 4-wheeler to fix up and sell, but I had no insight into market volume, what a good price was, and the likelyhood of re-selling at a profit. Many additional interests came into play, but this was the primary motivator.
Challenges
- This was my first proper foray into full-stack development. I had just finished a course with my masters program aimed at using cloud platforms for AI/ML Deployment.
- Scraping Craigslist reliably at scale and expanding national coverage.
- Interactive web UI and geographic heatmaps populated with user search results.
What I learned
- Designing and deploying a full-stack, AWS-hosted application end to end.
- End-to-end data pipelines and working with a relational database.
- The importance of starting a project with a directory structure that enables modular scaling.
- Solving problems with early AI coding tools, back when they needed a lot of hand-holding.
Status & next steps
The core premise — monitoring public activity at scale — still holds, and I like it as a way of surfacing signal from noisy public data. Much of what I learned here carried directly into MarkEverything.